AsteroMoE: A Faster MoE Kernel for Blackwell
See repo here: https://github.com/Asteromorph-Corp/astero_moe
Introduction
MoE GEMMs
In MoE GEMMs, or grouped GEMMs, we have a variable number of tokens for each expert. Suppose we have tokens at the beginning of the MoE layer, with a hidden size of . Each token is routed to experts out of a total of . After we compute the MoE routing, we will then have a tensor with a vector of routing indices, sorted by sequence order. We call this the pre-gathered layout.

However, most MoE GEMM APIs such as DeepGEMM and CUTLASS want a layout sorted by experts, with tokens for each expert aligned to a block (which makes index calculations easy). We call this the sorted blocked layout. However, this approach can, in the worst case, require tokens of padding: to put this into perspective, this can be up to tokens’ worth of padding with . Furthermore, gathering the tokens into their sorted positions also takes up a separate kernel and wastes memory bandwidth.
sonic-moe’s approach was to relax this alignment requirement in its output layout, so that tokens were still sorted by expert but packed together. We call this the sorted packed layout. It also fused the token gathering into the MoE GEMM itself, to allow the GEMM to directly recieve a sorted packed layout as input. This helped them get better-than-DeepGEMM performance on H100s while using much less activation memory.
AsteroMoE allows all three layouts as input, and can output either the sorted blocked or sorted packed layout for maximum flexibility.
Motivation
sonic-moe uses cp.async non-bulk instructions for gathers, and this was the optimal choice for Hopper. But if we look at the PTX documentation, the gather4 and scatter4 variants for tensor TMA were added from PTX 8.6 for Blackwell. So why don’t we use them?
Part of its reason may be that framework support is spotty; gather4 is not (yet) supported on C++ CuTe, CuTeDSL, Pallas Mosaic GPU, Mojo or ThunderKittens, but exists on Gluon and maybe cuTile. But why haven’t frameworks supported it? My speculation is that the current consensus seems be that cp.async instructions (also known as LDGSTS from the SASS instruction) are enough.
Even though gather4 and scatter4 might sound great, they do not transfer that much data. A TMA gather4 can only load 4 rows in 2D, and using the biggest possible 128B swizzling restricts our continuous dimension to size 128B, which means we can only transfer 512B per instruction. Interestingly enough, cp.async can have up to 16B transfer sizes per thread, which would mean 512B per warp, same as a gather4 instruction. So it might seem there is no benefit in using TMA. However, cp.async requires the kernel to compute the swizzled addresses since it does not use TMA, which ultimately requires more registers and takes up a little more latency. In our final kernel, we use 3-4 warpgroups depending on whether we use large inputs or small inputs; with the 4 warpgroup configuration, we use 32-48 registers per load warpgroup. It is plausible that the gather4 instruction helps with this register pressure (and perhaps also with automatic load predication).
Unlike other platforms which require obscure escape hatches to use lower level behavior not explicitly exposed to the programmer, C++ allows you to specify the PTX instruction as you wish, so we’re free to implement gather4/scatter4 by ourselves.
Results!
Here are the results for DeepSeek V3 on a single B200 GPU:
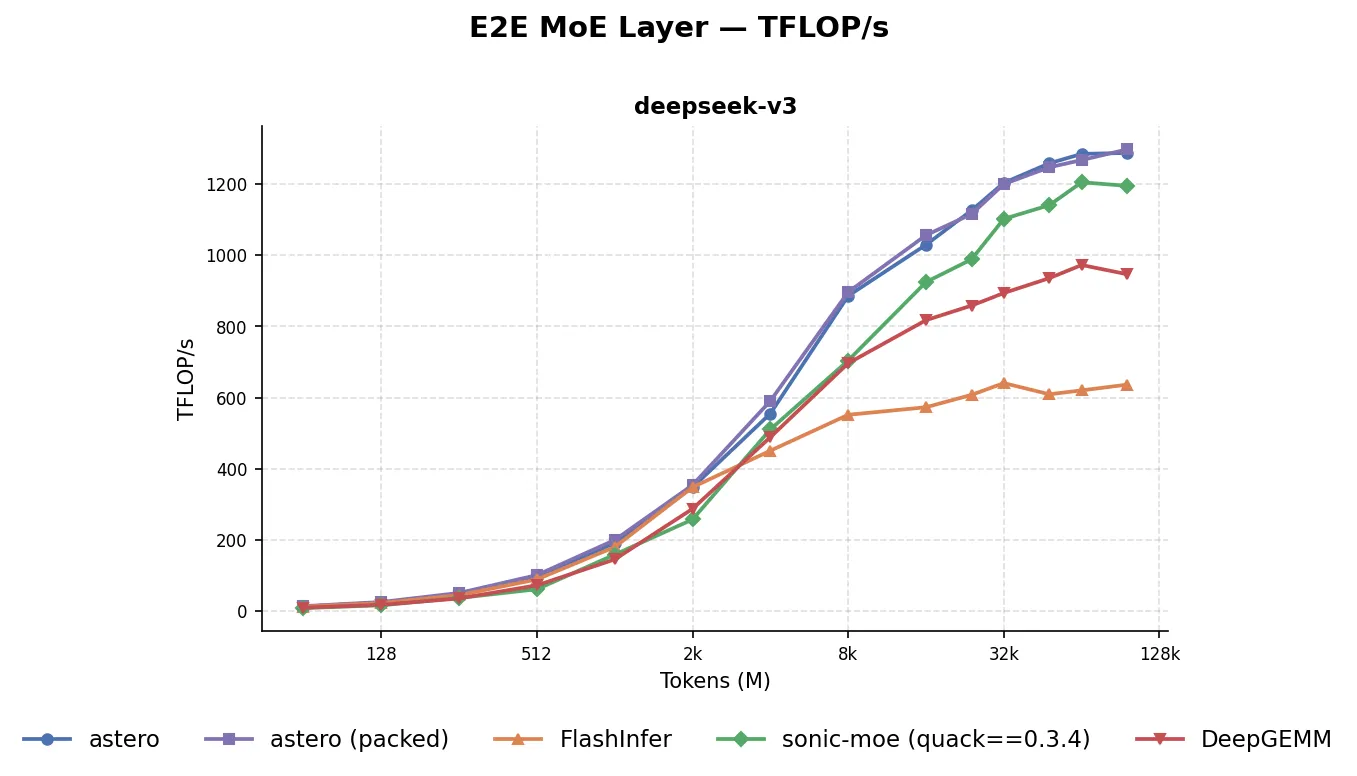
The blue default AsteroMoE configuration uses the sorted blocked layout for the MoE intermediaries; the purple packed configuration uses the sorted packed layout. We see that both configurations achieve better performance than sonic-moe across all batch sizes; in fact, even though we did not particularly design the kernel for small batch sizes, we win against Flashinfer’s CUTLASS fused MoE kernels for batch sizes as low as 64. Finally, the sonic-moe used here is a patched, fully-tuned version that uses quack-kernels==0.3.4; the release version at the time of this blog post uses quack-kernels==0.2.5 and has worse performance.
The TFLOP/s are based on the end-to-end (including the router forward, metadata computation, and summing back to tokens) timing results, with a scaled normal distribution, and without storing intermediate activations. We used the same (modulo minor modifications) routing kernels for SonicMoE, DeepGEMM, and AsteroMoE.
Tile Scheduler
sonic-moe’s tile scheduler linearly goes through the expert token counts in counts of 32, and recomputes the tile count (ceiling division via the tile size) and its prefix sum on the fly. In AsteroMoE we use more shared memory but do a little less compute by converting the token count array in global memory to a tile count prefix sum array in shared memory. Via storing separately the tile prefix sum for every 32 experts, we can do a search for a specific tile index in 2 warp ballots as long as the total count of experts is not greater than 32² = 1024. (In practice, we’re limited by shared memory, and we use the u16 dtype to support up to 512 experts.)
We could also have tried to store the tile count prefix sum in a separate kernel and take it as an additional input, but this can have the disadvantage of making the block size a part of the interface. If even finer grained experts become the norm, this approach might be better.
Load Pipeline
TMA instructions can only be issued by one thread per warp at a single time, which means we need to employ multiple warps if we wish to fill the TMA pipeline faster. We can use an entire warpgroup to issue gather4 instructions, 4 at a time. However, the indices themselves also have to be fetched from global memory, as these indices must be in registers to issue the TMA gathers. Thus we use a separate index loading warp. We use the cp.async.ca instruction to load these; it’s asynchronous, but it also supports loading values of size 4B with only a 4B alignment requirement (TMA bulk loads would also work, tensor or not, but these have a 16 byte alignment restriction). When using the cp.async.mbarrier.arrive instruction on multiple threads to make the loaded indices visible via a mbarrier, we found the mbarrier can overflow even though the PTX docs say the arrive count is incremented before decrementing to give a change of net zero. To fix this, we use the noinc variant and set the arrive count to 32 for each thread in the dedicated index fetching warp.
MMA Scheme
For the MMA, even though the natural PyTorch dimension assignment is M=Batch, N=Out, K=In for a [M,K], [N,K] MMA, we flip the arguments and instead use M=Out and N=Batch. This is because M seems to be more sensitive to performance, and only offers 128 and 256 as possible input sizes. In contrast, N offers all multiples of 16 from 16 to 256. We find that for small batch cases, setting the Batch block size to 64 helps with performance.
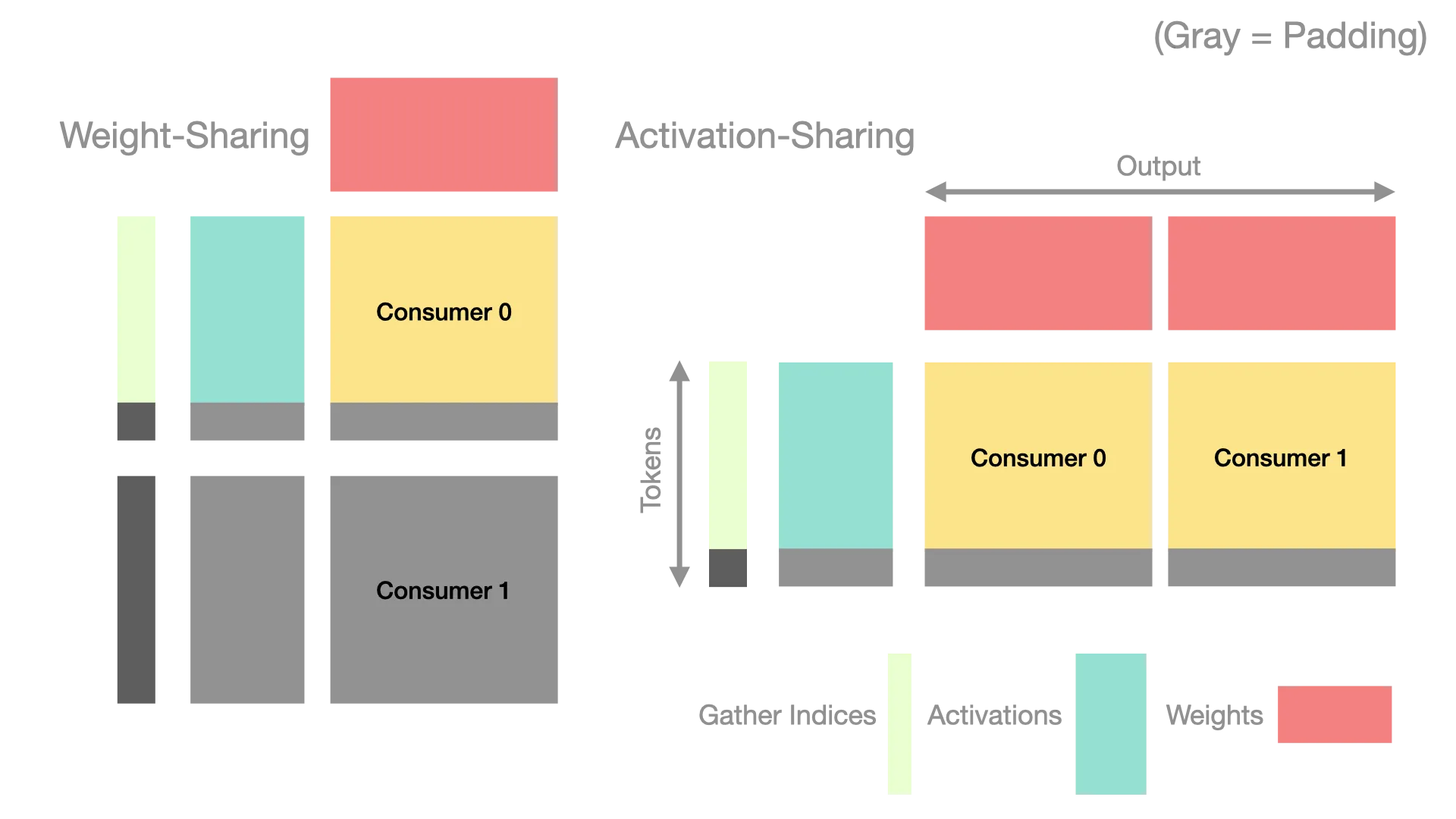
Furthermore, for the 2-consumer cooperative MMA configuration, reported by Hazy Research and CUTLASS to be faster for large inputs, we also share the activations ie the [M,K] matrix instead of the weights between the consumers, since the activations are more expensive to load (for example, we have to use gathers, and we also have to load indices), and is also more likely to be padding than weights. This results in configurations where the overall cluster block size (Batch, Out) ranges from (64, 256) (with one consumer) to (256, 512) (with two consumers).
Epilogue
The epilogue is relatively less interesting: we store the outputs, along with the swiglu values. One of ThunderKittens’ weaknesses shows here: we can’t “just” reduce pairwise, and we must think through how the registers are distributed between threads. We use some slightly ugly constexpr + lambda code here (it can probably be much cleaner than now), but we still support both gate and up first layouts for SwiGLU. The interleave-by-one path can be probably optimized, perhaps by using a different tensor memory load instruction to reduce the number of warp shuffles, but it is functional. We do have to apply a transpose when storing since we flipped the Batch and Out dimensions in the matmul; the most convenient place to do this is when issuing the stmatrix instruction to store registers into shared memory, since it supports transpose natively.
We do not use scatter4 to fuse expert summation since scatter4 does not support atomic reductions. However it is still used in the kernel to support the packed layout. Even though normal TMA stores can recieve a unit coordinate token offset, they cannot mask out stores partially, leading to workarounds such as this paper and Tokamax using a logarithmic ladder of tiles. Since scatter4 ignores out of bound store offsets, we can use this feature to mask out invalid tile portions.
Memory Hazards
When we were writing the kernel’s tile scheduler code, we discovered an interesting behavior:
// Warp 0
int x = smem[0];
warp::sync();
if (warp::elect_leader()) arrive(mbar);
// Warp 1
wait(mbar, phase);
if (warp::elect_leader()) smem[0] = __ldg(gmem);The above ThunderKittens code results in a data-race (when looped multiple times). This is despite the warp::sync() call which is equivalent to __syncwarp() and the bar.warp.sync PTX instruction. The problem is that even though the bar.warp.sync instruction guarantees that memory accesses (within the warp) are made visible to all participants, it is not a synchronizing operation in the PTX memory model which orders memory reads and writes.
When we were writing the kernel, this bug happened: when a non-scheduler warp read the scheduler data, did a warp::sync(), and then arrived on a mbarrier on a single thread to signal that it was done reading the data, a conflict occurred at the scheduler data address. The fix was to use warp::sync(barrier_id); if memory accesses need to be ordered when synchronizing a warp, since it maps down to bar.sync which is a synchronizing operation.
Barrier Ring Management
Trying to track ring buffer indices through loops that could be skipped (due to a tile not having any tokens) was quite difficult, so we wrote a RAII-based barrier index manager. Although CuTeDSL and the quack library which uses it employs barrier pipeline types, it has a constrained API of a producer-consumer pattern. However, in the kernel, we use a schedule_arrived → schedule_computed → schedule_finished 3-cycle scheme, which wouldn’t map cleanly to such an interface. Furthermore, although the wait instruction is same for all barriers, there are many ways to arrive on a barrier (mbarrier.arrive, cp.async.mbarrier.arrive, mbarrier.arrive.expect_tx, etc…). Instead of creating a pipeline type for each pattern, we opted to only track indices and arrive explicitly for each case.
Acknowledgements
We’d like to give credits to ThunderKittens for providing an excellent library to program GPU kernels in, and sonic-moe for the original gather kernel design.